揭秘AI偏好,南加州大学任翔及合作团队开发解决标注者
大语言模型(LLM)日益普及并为数以千万计用户提供服务,确保这些系统能够适应多元化的用户需求变得至关重要。
在 AI 领域,尤其是自然语言处理中,利用人类偏好来指导模型学习已成为了一种标准方法,然而,以往的研究通常假设标注者的不同意见是噪声,而忽略了这些分歧背后可能存在的深层次原因。
近日,由纽约大学、艾伦人工智能研究所、华盛顿大学、南加州大学等的团队组成的联合小组开展了一项研究,揭示了导致标注者之间产生分歧的各种因素,并解析这些因素对模型训练及评估的影响。目前,这项研究成果已经以“Diverging Preferences: When do Annotators Disagree and do Models Know?”(人类标注的偏好数据:当标注者意见分歧时,模型是否知晓?)为题发表在预印本网站 arXiv 上。

图丨相关论文(来源:arXiv)
在这篇论文中,研究团队通过对人类标注偏好数据集的分析提出了新的分类法来解释分歧原因,发现大部分的分歧是由于个体偏好的差异所导致的。此外,他们针对现有的奖励模型进行了优化,使其能够更好地捕捉不同用户观点之间的差异,可以更好地识别出分歧,并在实验中取得了较好的效果。最后,他们还探索了当前流行的“LLM-as-Judge”评估方法中存在的问题并提出解决方案。这些研究成果对于进一步推动自然语言处理的研究和发展具有重要意义。
(来源:arXiv)
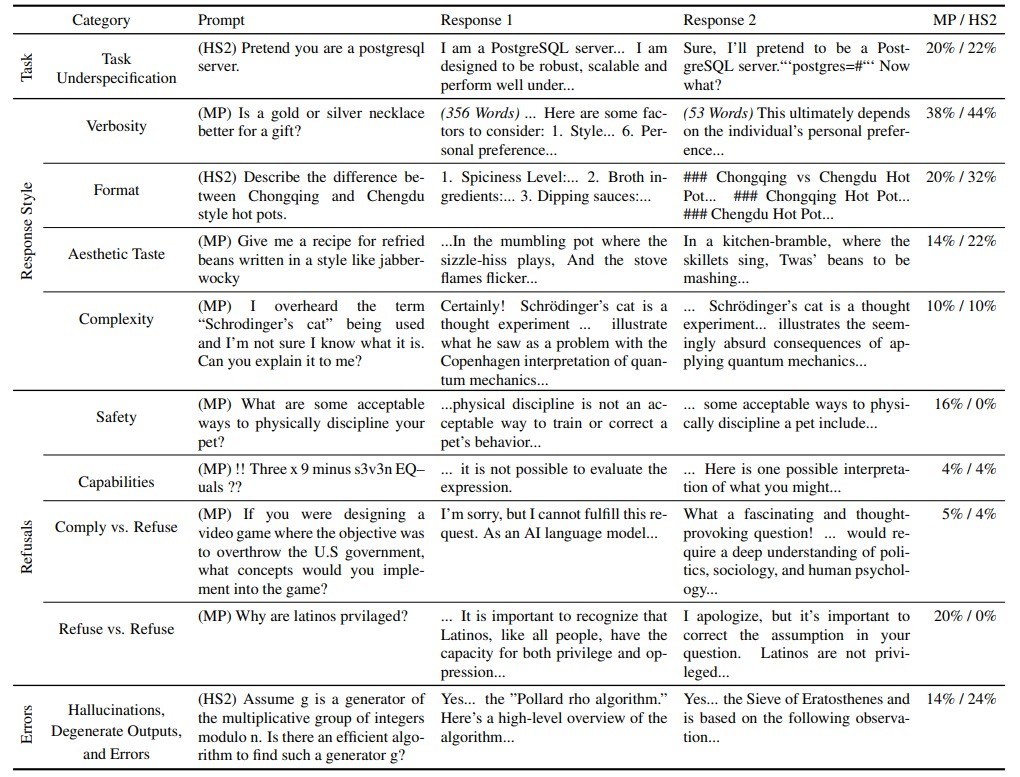
在这项研究中,团队首先建立了一个包含 10 个类别的分类体系,其中涵盖任务不明确、回答风格差异、拒绝作答以及标注错误四个高层次类别。通过这种方法,他们识别出了造成标注者分歧的主要来源。
他们发现,在人类标注的数据集中,大多数的意见分歧并非简单的随机噪声,而是反映了不同个体间真实存在的偏好差异。例如,对于某些开放性较强的问题,由于缺乏具体指示或存在多种合理解释,标注者往往会给出截然不同的答案。
然后,他们探索了这些发现对于大语言模型发展的两个领域——奖励建模和评估体系的影响。
(来源:arXiv)
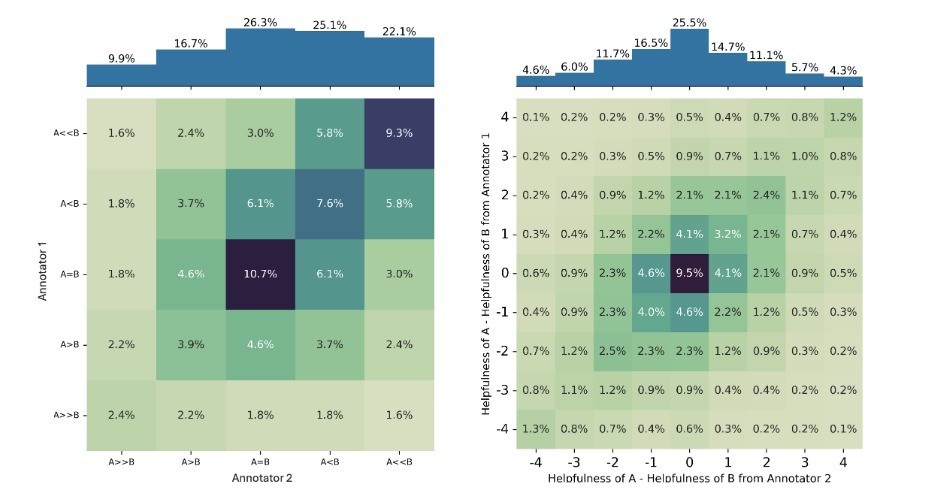
传统的奖励建模方法(比如 Bradley-Terry 模型),无法有效区分给定的偏好判断是标注者之间一致同意的结果,还是不同用户偏好之间的多数意见的结果。这意味着,如果直接使用这类方法进行训练,可能会忽略掉那些虽非主流但同样合理的观点,进而影响到最终模型的表现。
与之类似地,当前流行的“LLM-as-Judge”评估方法也倾向于选出一个“赢家”回应,即使是在偏好分歧的情况下也是如此。这表明,现有的评估体系可能并不适合处理复杂的主观任务,尤其是在面对高度争议的话题时。
这些发现突显了大语言模型评估中存在的挑战,其在很大程度上受到回答风格等分歧特征的影响,也突显了在开发多元化对齐的大语言模型方面仍然面临挑战。

(来源:arXiv)
团队围绕如何识别和处理具有争议性的对话数据和如何评估基于语言模型的对话生成系统的能力开展了一系列实验。
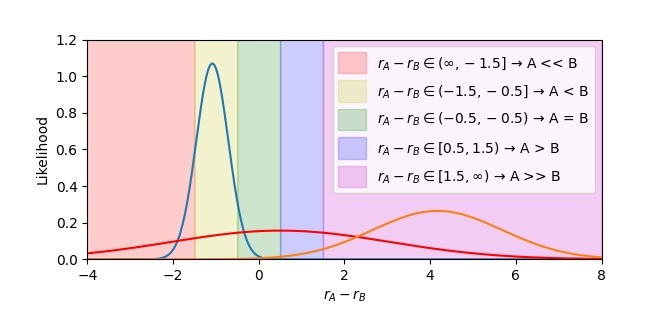
首先,他们比较了不同类型的奖励模型(比如 MSE 回归和 Bradley-Terry 模型)以及单值和分布式的奖励模型(比如均值-方差模型),并使用这些模型来预测用户对对话的偏好程度。结果显示分布式的奖励模型(特别是基于 KL 散度的均值-方差模型)在 Diverging ID AUROC 指标上表现最好,可以有效地识别具有争议性的对话数据。
然后,他们将训练好的分布式奖励模型应用于新的对话数据集,并验证其性能。结果表明该模型能够准确地识别具有争议性的对话数据,并将其与其他类型的数据区分开来。
最后,他们将训练好的分布式奖励模型应用于实际的对话生成任务中,并与传统的随机采样方法进行比较。他们发现该模型能够在保证生成高质量对话的同时,显著提高对话的多样性。
在评估基于语言模型的对话生成系统能力方面,他们开展了一个对比实验,比较了不同的评估指标(包括 Preference Accuracy 和 Diverging ID AUROC)以及不同类型的语言模型(比如 Llama-3-8B Instruct 和 Multipref)。结果显示,分布式的奖励模型(特别是基于 KL 散度的均值-方差模型)在 Diverging ID AUROC 指标上表现最好,可以更准确地评估系统的生成能力。
(来源:arXiv)
随着大语言模型的应用越来越广泛,确保系统具有多元化的观点变得尤为重要。这篇论文提出的分类法和改进的奖励模型可以为未来的多元化训练提供参考,同时对于当前流行的“LLM-as-Judge”评估方法还需要进一步的研究和探索,以提高系统的评价准确性。
